基础监控系统:浅谈数据采集
随着互联网的发展,运维工作的复杂度成倍增加;与之关联的,各种运维平台的复杂程度也在成倍增加。 在此场景下,如何最大程度满足稳定性工作需求,并保证我们的系统相对的干净与解耦,是我们一直在追求和探讨的。 监控系统的话题,很大。 本篇文章为笔者监控系列文章第一篇,仅介绍监控系统的采集环节。
前言
监控系统的话题很大,随着业务的复杂,也会衍生出各种各样不同的形态。但总体上绕不开三个部分:采集、存储、报警。 本文跟大家谈谈第一部分:数据采集。
哪些数据需要采集
说到采集,首先我们应该了解,哪些数据需要被采集。 监控系统可能是为了满足实时的数据查看、可能是用作历史状态回顾、或者用来做异常告警等。这些都需要收集到准确的数据。 而数据采集,其实就是为了收集足够的数据,来满足各种各样的业务需求。
-
基础数据 基础数据,观察服务器状态的基础指标。 包括CPU、内存、网络、IO等等类别,这里就不一一列举了。 另外,类似core、OOM等信息,也可以考虑采集,算作基础指标。
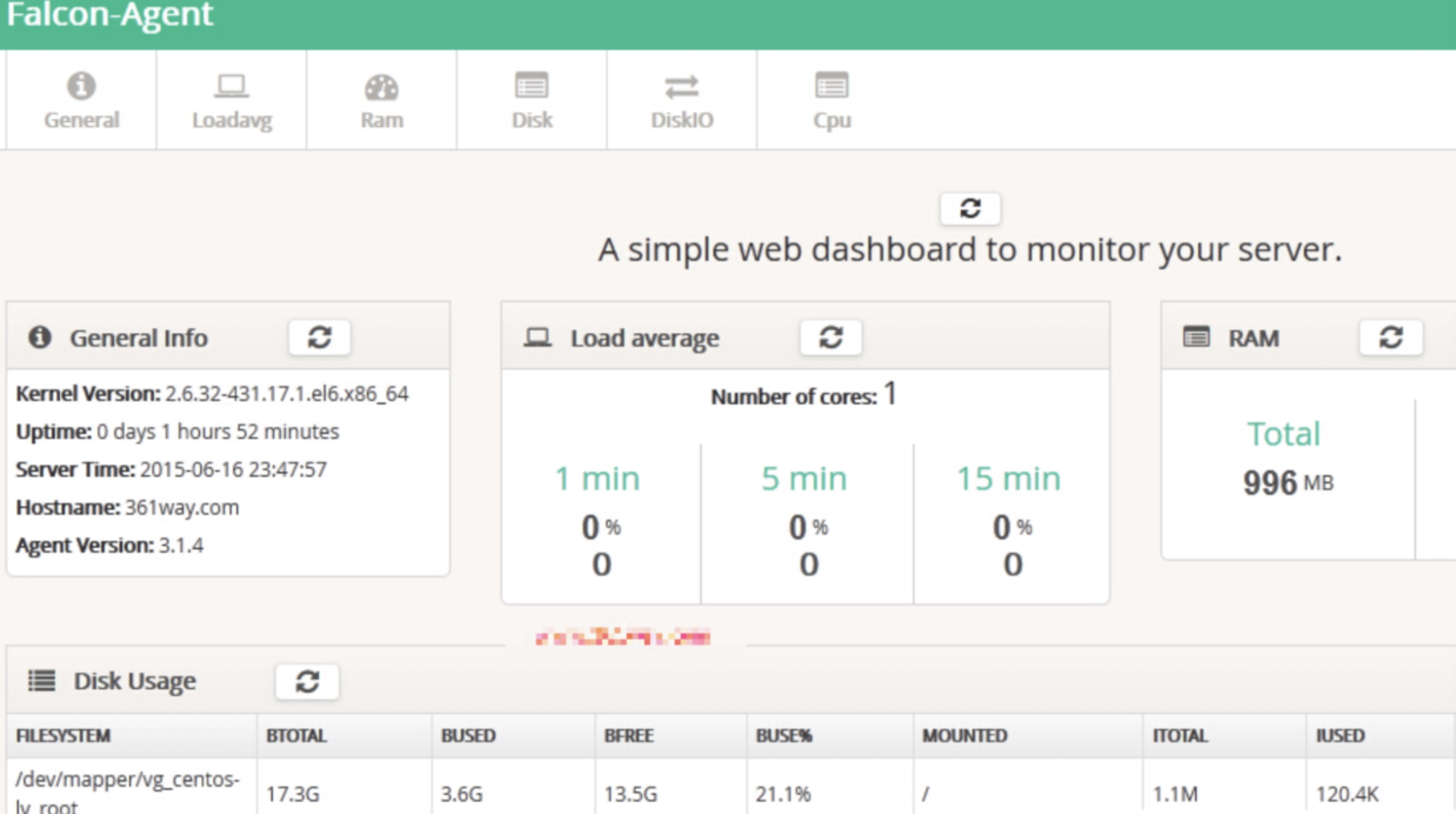
Open-Falcon基础指标
-
应用数据 应用数据,指的是在服务器上运行的应用的状态数据。 例如端口存活、进程存活、进程资源消耗等。 这部分数据最大的用处可以对自己的服务添加存活告警,追溯进程资源的历史占用情况。
-
业务数据 以上两类数据,都是我们需要关注的,但是在平时的稳定性工作中,我们会对硬件和业务都做出相应的冗余。因此,我们仍然
需要一个确定的指标,来标示我们的业务运行状态。 这个指标,我们称为业务指标。 要判断一个业务是否完全正常,不是说服务没挂就没问题了。变更造成的逻辑问题、错误数据造成的影响、数据量太大造成的响应超时都无法通过应用的存活状态来发现。 一般来讲,用来判断业务的状态,我们习惯观察三个黄金指标:流量、错误率、延迟。 这三个指标,可以比较完善的从多个角度来判断业务状态。 当然,根据业务情况的不同,也会有很多其他维度的指标,都算在业务指标的范畴之内。
数据模型
要讲采集的方式,必须要从监控的数据模型讲起。
监控的数据,其实是最纯粹的时间序列数据。那么,在建设一个监控系统的时候,抽象出统一的数据模型,应该是设计和架构的第一步。
一般的时间序列数据包括四部分:
- 数据名称(指标名 / metric)
- 标签(标签 / tags)
- 时间戳(timestamp)
- 值 (value)
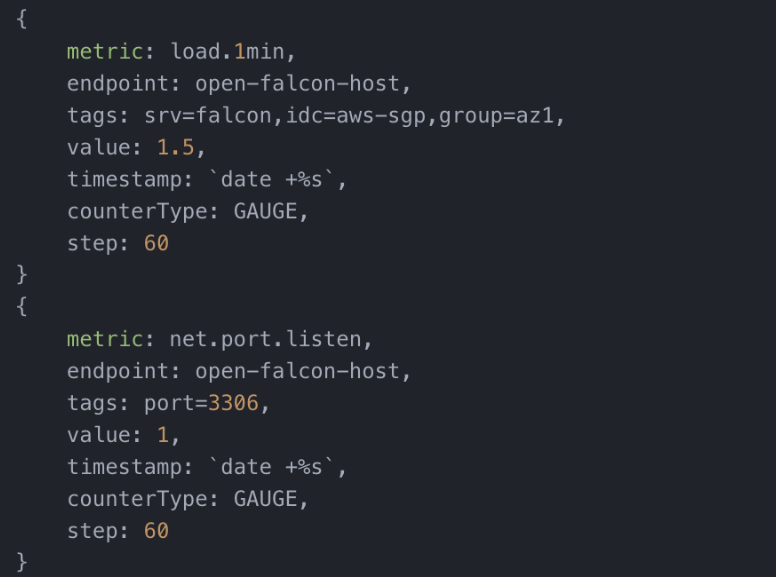
Open-Falcon数据模型
如上图,是open-falcon的数据模型,这个数据模型在基础的时间序列模型上做了一些定制化,增加了endpoint和counterType两个字段。
这两个字段,与open-falcon的形态以及存储细节都有所关联。但如果再宏观一点来看,可以把这两个字段看成两个标签,只是单独拿出来了而已。
采集的方式
采集的方式根据我们的监控数据来源的不同而不同。主要分为默认采集、插件、探测、日志、埋点几种。
-
默认采集 默认采集一般是在默认的agent内做采集,比如cpu、内存、IO等机器的基础指标,进程监控的相关指标,都算在此类。 这类指标一般是在agent里预定义好的,指标量不会增长太多。
-
探测式采集 顾名思义,外部探测式的采集都属于这一类。 比如端口监控、Ping监控、HTTP监控、网络监控等等。
探测式的采集,属于外挂式的采集。这类采集比较轻量,对系统的侵入性较小,通过简单的配置,可以快速的看到效果。 除网络监控本身之外,这类监控有一个显著的特点,就是
严重依赖网络,一旦网络有抖动,极易发生误报。因此可以采取多点探测的方式,这样可以在一定程度上防止误报的发生。 -
业务埋点 没有人,比业务的开发同学,更了解自己的系统,更知道什么情况下应该观察哪些核心指标。 因此对于业务采集做出标准化是非常必要的一件事情。笔者公司有一个原则:
坚持业务指标采集是代码的一部分原则不动摇,提高指标覆盖率。业务的稳定性指标应该是开发的工作内容之一。模块自身的可运维性应该是工程的开发标准之一。 为此,运维需要给出稳定性的监控覆盖标准:- 流量
- 错误率
- 延迟(99分位、95分位、90分位、avg) 同时,可以使用tag对服务的调用双方进行标记,如caller和callee。也可以由开发同学自定义加入一些标签。
所有运维标准的制定,没有相应的工具和平台支撑都是空谈。因此监控系统同时应提供各种语言的业务埋点SDK,以及快速简单收集数据的平台。 大部分开发团队,都有自己的一套开发框架,如果能深入业务,也可以进一步考虑,将埋点SDK直接集成至业务线的统一开发框架中。
-
日志监控 从稳定性角度来看,大部分情况下,日志监控与业务埋点获取的是同样的数据。 只是日志监控更加灵活,当我们的服务是闭源的项目,或者短时间内无法快速对所使用开源的组件做出修改进行埋点的场景下,日志监控可以快速见效。 一般来讲,日志监控分为
在线日志采集和离线日志采集。在线日志采集,一般来讲会更灵活些,可以通过各种自定义的操作,对日志的时间、内容、量级都进行很好的筛选和计算,只需要少量的配置成本即可。但这种日志采集,侵入性较大,需要在机器上安装agent,且实时对日志进行分析会占用CPU资源,极有可能影响线上服务稳定性,因此一定要做好资源限制。 离线日志采集,是将日志统一收走,在中心处理计算。这种采集的优点在于不会占用太多的CPU资源,没有日志量的瓶颈。但同时,也会占用大量的网络资源。时效性上,跟实时分析相比,会有一些延迟;再就是大批量的日志集中处理,一定要对日志的格式进行规范,因此灵活性上可能会差一些。
-
插件采集 基础的指标有了,埋点、日志、探测也有了。其他的呢? 用户如果有自己的采集方式,但是需要将数据上报至监控系统,这种场景,可以用插件采集来实现。 插件采集提供了一种,由监控系统控制采集周期,用户只需要实现一个周期的采集逻辑即可完成数据收集的能力。 插件采集更加灵活,可以提供用户自定义的采集方式,比如说特定的收集命令,如jum等。插件只需要上报监控系统制定好的规范数据即可。 插件采集,需要周期性的在机器上执行插件脚本,因此这个脚本的审计一定要把好关,无论是损害性动作还是资源消耗,都可能成为影响线上稳定性的隐患。
-
自定义指标上报 除了上述的几种采集方式之外,监控系统还应支持自定义上报的功能。 用户自定义的时间序列,都希望能统一使用监控系统进行数据可视化以及告警的功能。 此时可以提供
自定义数据上报的接口,无论是通过本机agent收集,还是有单独的中央收集器都可以。 有了自定义指标的上报,监控系统才真正成为一个稳定性基础设施。 open-falcon的采集agent,就提供了这样的接口。 不过,支持了自定义,但是用户的上报行为却无法很好的规范。生产环境经常出现误上报数据或使用不规范的情况,将监控系统存储打到瓶颈的问题。此部分我们会在《运维监控系统专题(二):脏数据的治理》来进行讨论。
数据的收集方式
一般的,有两种收集方式:
- 中心端主动拉取(prometheus)
- 客户端自动上报(others)
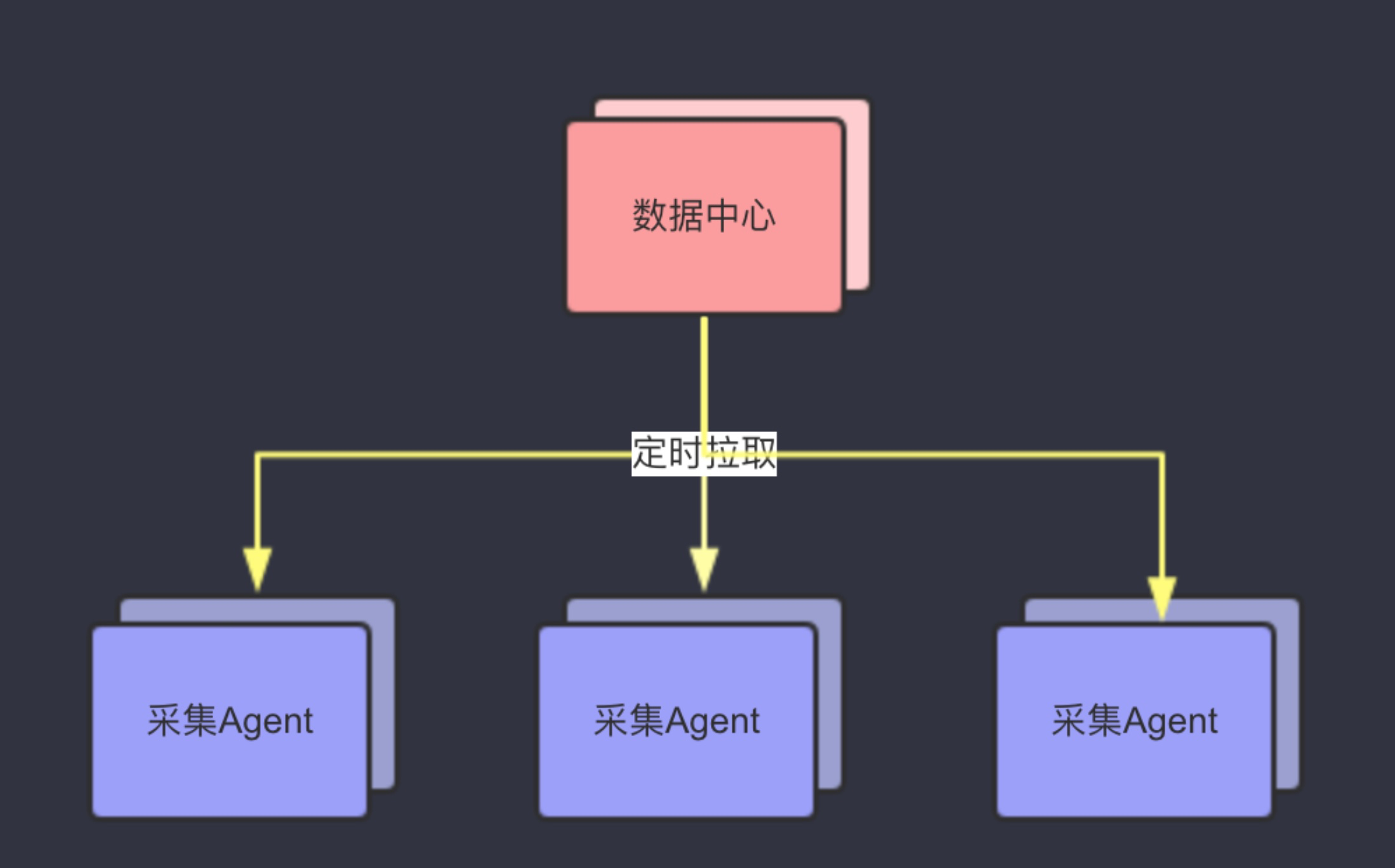
中心端拉取模型
中心端主动拉取,就是由一个中心端定时的向采集端按需拉取数据。这种模式的优点在于可以按需拉取,不会有浪费。但是在这个模型中,中心承担了过大的压力。理论上性能会有很大的瓶颈。
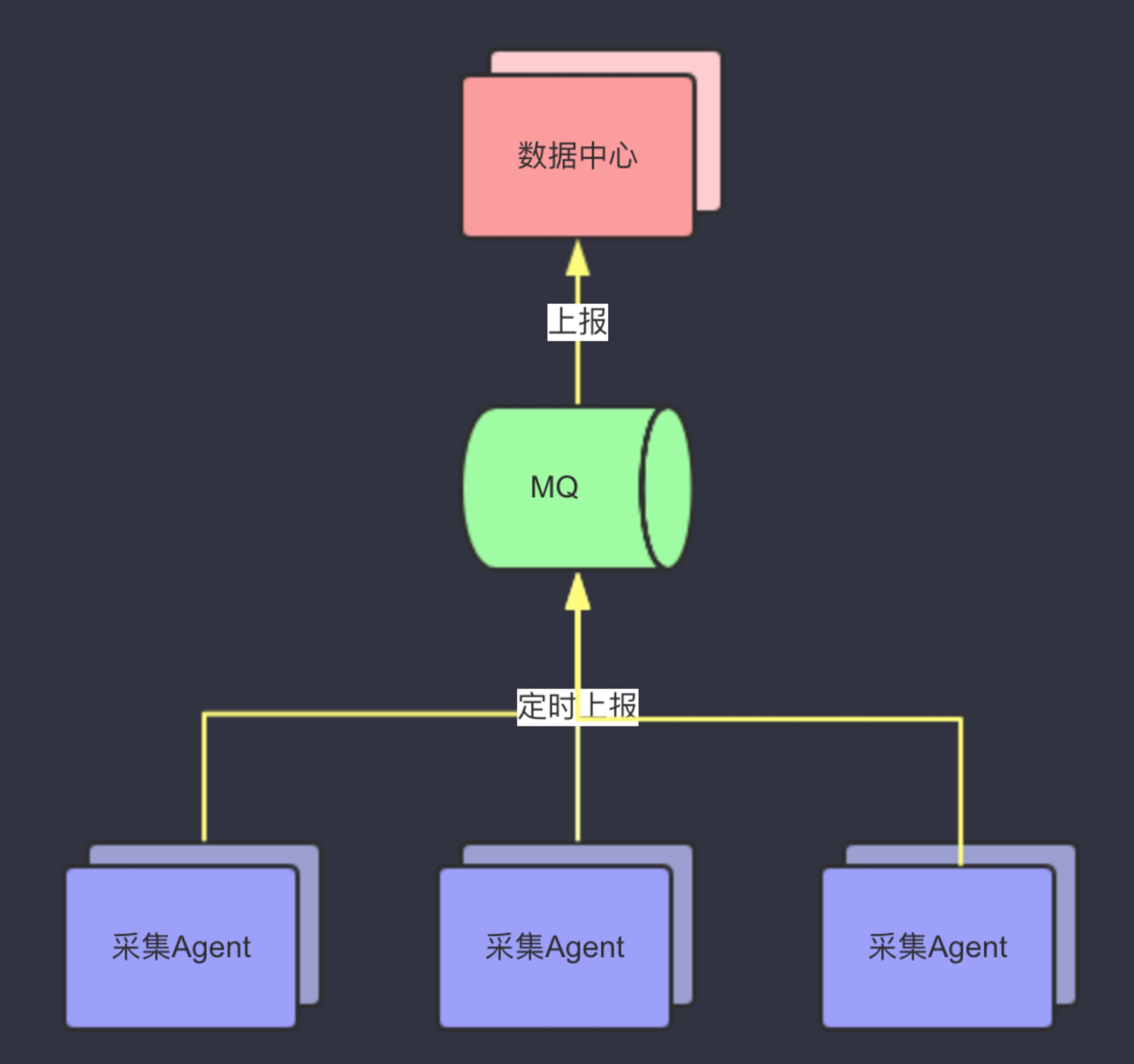
agent推送模型
客户端自动上报,就是所有数据一视同仁,全都上报。一般来讲,会采用一个统一的proxy来收集,后边会考虑做多级的组件,或者加一层MQ等,都是可以考量的设计。 整体来讲,如果预估监控数据的量比较大。还是建议采用自采集然后集中上报的模式。
open-falcon的数据收集就是很好的客户端自动上报模式。transfer可以无状态伸缩、且支持级连。
2018.10.22