Falcon-Graph扩容二三事
前言
监控系统是整个运维环节,乃至整个产品生命周期中最重要的一环。而Open-Falcon是目前业界做的最开放、最好用的互联网企业级监控产品。 Open-Falcon的底层存储,使用RRDTool时间序列数据库。在Transfer & Query模块,使用一致性哈希来对数据做均匀的分片。完美的满足了海量数据的存储以及高效、快速的查询。 然而当存储、IO、或者某一方面资源到达瓶颈的时候,我们的存储组件就需要通过扩容来继续满足使用的压力及需求。 本篇文章就将我们扩容的经验及过程分享给大家。
本文面向对象
1、Open-Falcon老鸟,但是没有经历过存储扩容,准备扩容的人。
2、眼一闭、一睁,啥也没管,就扩容完成了,心里还是有一点懵逼的人。
方案原理
本篇文章不讨论代码细节,这里对应扩容步骤简单给大家讲下原理。 从修改transfer开始,流量会按哈希规则进入到原始集群和扩容集群。 此时扩容集群发现,migrate开关是打开状态。 于是,扩容集群接收到流量之后,并没有很着急的去落盘,而是先Trans一份给老的集群。同时会尝试从原始集群中拉取RRD文件。拉取成功,则落盘。拉取不成功,等待超时再落盘。 同样的,Query的查询,也是按照哈希规则。到了扩容集群的查询,如果Graph发现,本地已有RRD文件,则直接查询返回。如果本地无RRD文件,则Graph会通过老的哈希关系,去原始集群中拉取到旧数据,然后跟自己cache中的数据做一个聚合,然后返回给查询者。 整个过程从技术上来说,可以说是:无损的、可以热迁移。
方案缺陷
整个方案,经过我们测试,比较稳定。但仍有如下缺点:
1、无回滚方案。开弓没有回头箭。一旦扩容失败,会导致扩容期间部分数据丢失。 2、自监控不完善。官方提供给我们的统计数据,只有迁移的成功、失败的数量等较少几个指标,在扩容过程中,很可能会导致操作者不能完全掌控扩容的详细情况。
扩容前,我们做了哪些准备
在扩容之前,由于此方案容错率较低,可以提前做一些准备,保证第一时间可以发现问题的所在:
补全自监控
【写】Transfer接收点数(实际扩容并不会影响这个数值,主要用于比较) 【写】Transfer转发点数 【写】Graph接收点数 【写】扩容集群Trans数据到老集群点数 【读】Query到Graph查询总次数 【读】Graph转发查询的次数、耗时、错误率 【迁移】迁移的成功个数/成功率,失败个数/失败率,迁移延迟
功能测试
很多公司都对开源版本的Graph进行了一些修改和定制。很可能会对这个过程有影响,之前笔者公司,对内存进行过优化,存储在内存中的数据格式有所变化。但是migrate时,哈希规则的计算正好依赖此数据。导致graph扩容时计算出来的的哈希值,与Transfer不一致,最终导致丢掉了一部分数据。 因此,在真正的扩容前,针对自己的公司Graph版本,进行一个准确性测试,是很有必要的。
压力测试
不同的公司,监控系统会有不同的量级和使用瓶颈。一般来讲,监控系统都是写入量大,查询量少。但是笔者所在的公司,由于重构了Judge,改原有的Transfer推送方式为Judge自行拉取。导致查询的量非常大,基本可以达到读写比 1:1的量级。 因此,在真正的扩容之前,进行一个与自己线上环境相符的压力测试,也是很有必要的。
跟大家分享下我们的压测结果: 测试环境:CentOS 7.2 内存:8 * 16G 硬盘:3.2TB Nvme SSD 扩容台数:2台 => 4台 压测过程中:单机持续写入130万点/秒,持续查询100W点/秒
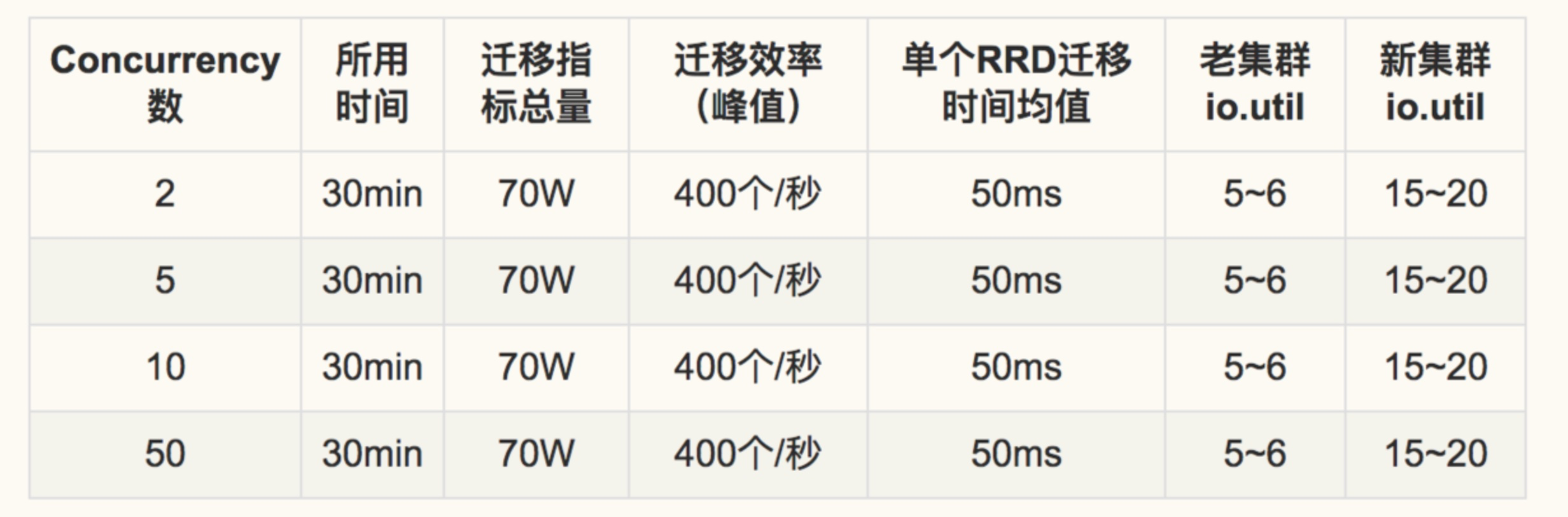
压测结论,各项指标正常,各项资源使用并没有明显增加。 concurrency的提高,并没有对扩容效率带来明显的提升。 但也从侧面证实了,此扩容方案,在读写比1:1的情况下,可以完美热扩容。
##扩容过程 ####分批扩容
30台 => 31台 (灰度1台) 31台 => 33台 (再小流量2台) 33台 => 38台 (再中流量5台) 38台 => 50台 (全量)
####扩容过程观察的指标
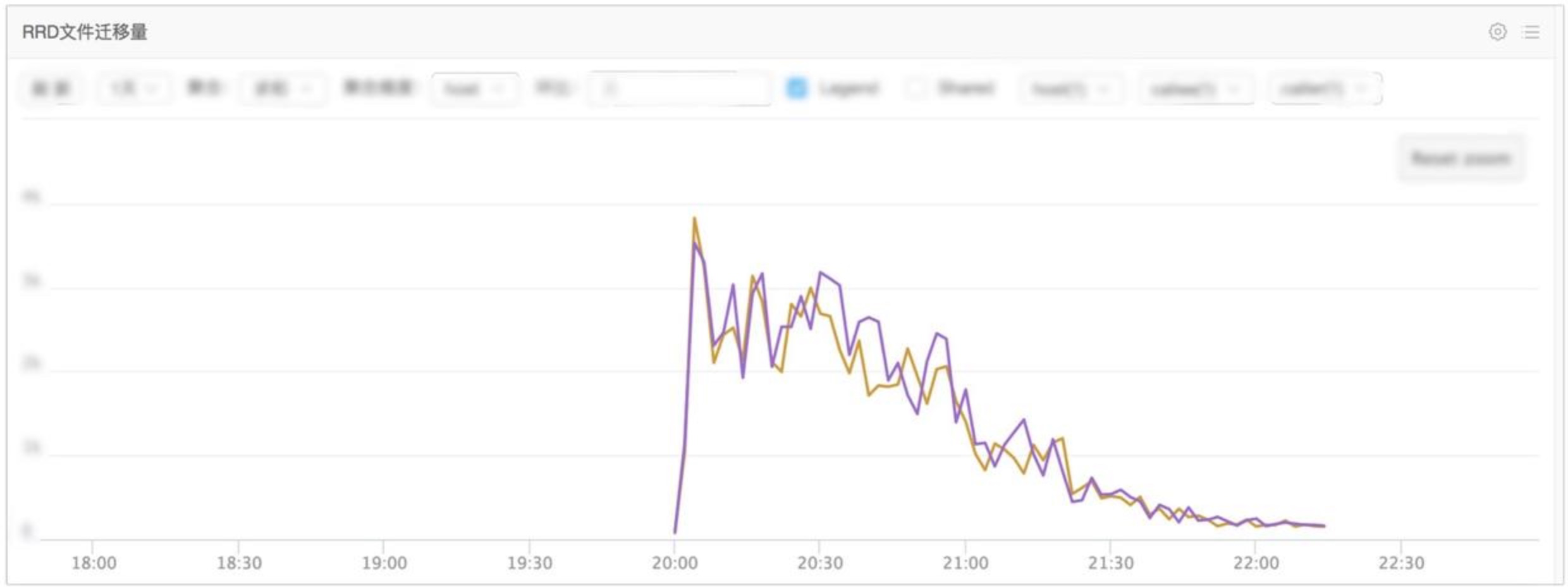
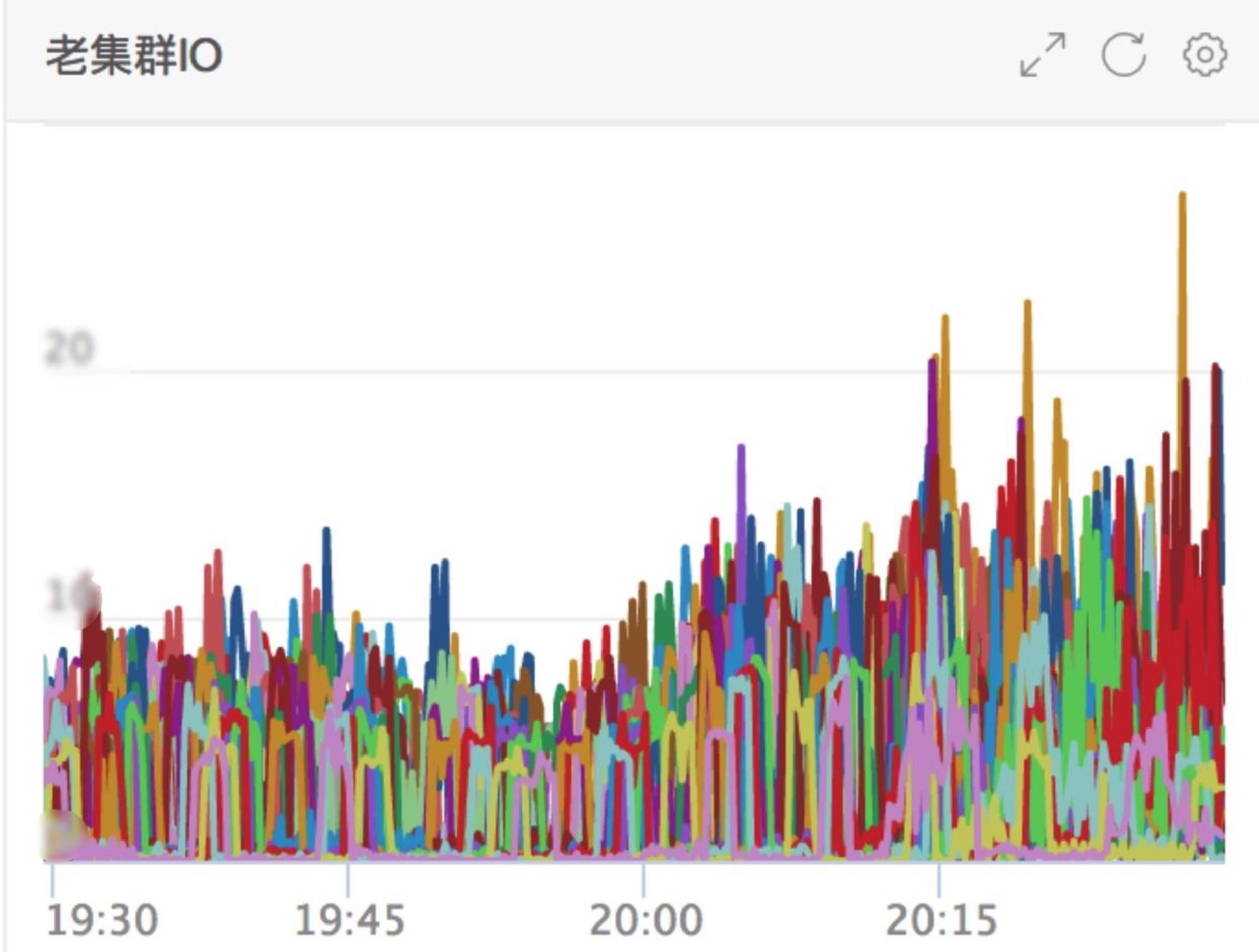
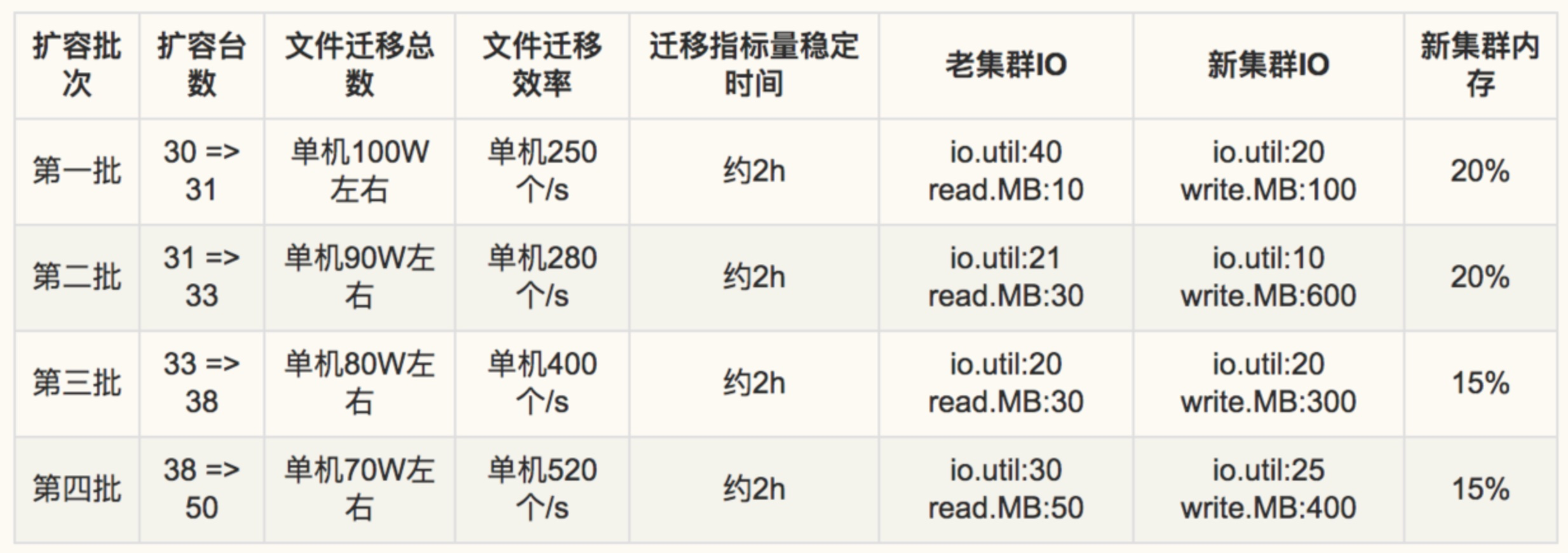
【基础指标】老集群和扩容集群的内存和IO情况 【写入链路】Transfer接收点数、Transfer转发点数、Graph接收点数 【查询链路】Query到Graph查询的次数、错误率、延迟。Graph转发查询的次数。 【迁移效果】RRD文件的迁移量、成功率、迁移时间。
####扩容过程中指标变化 每次扩容,都严格遵守扩容步骤,观察所有性能指标及数据的稳定性,并没有出现严重的断层及数据异常。下面将我们多次扩容的性能及指标数据分享给大家:
所有concurrency配置为:5
####如何确保扩容完成
1、Graph接受指标总量稳定,且与Transfer转发指标数持平 2、所有查询量没有跌,且所有查询错误率稳定 3、迁移RRD文件数及迁移效率,逐渐稳定。趋于0或一个固定的值。(若无新指标,会趋于0) 4、找N个确定会落在扩容集群上的指标,确定这N条线的数据,连续且并没有断开。
##需注意的点 ####重启有害 扩容过程中,没有完成RRD文件迁移之前,扩容集群重启就意味着扩容失败: 重启时,内存中的数据会被强制落盘,导致未迁移完成的RRD文件无法再次迁移。
####建议分批扩容 由于此方案无法回滚,对于数据敏感的场景,建议考虑分批次扩容。 此次扩容过程中,我们就采用了分批次扩容的方案。先灰度一台,再小流量2台、3台、5台,直至最终完全上线。 实际证明,分批次扩容是完全可行、安全,可以降低风险的。
##总结 总而言之,这个方案是可行、稳定、可操作的。只要做好事前准备,对扩容过程了解到位,可以很容易扩容成功。
##附:扩容中的指标变化情况